Tokenwisehq
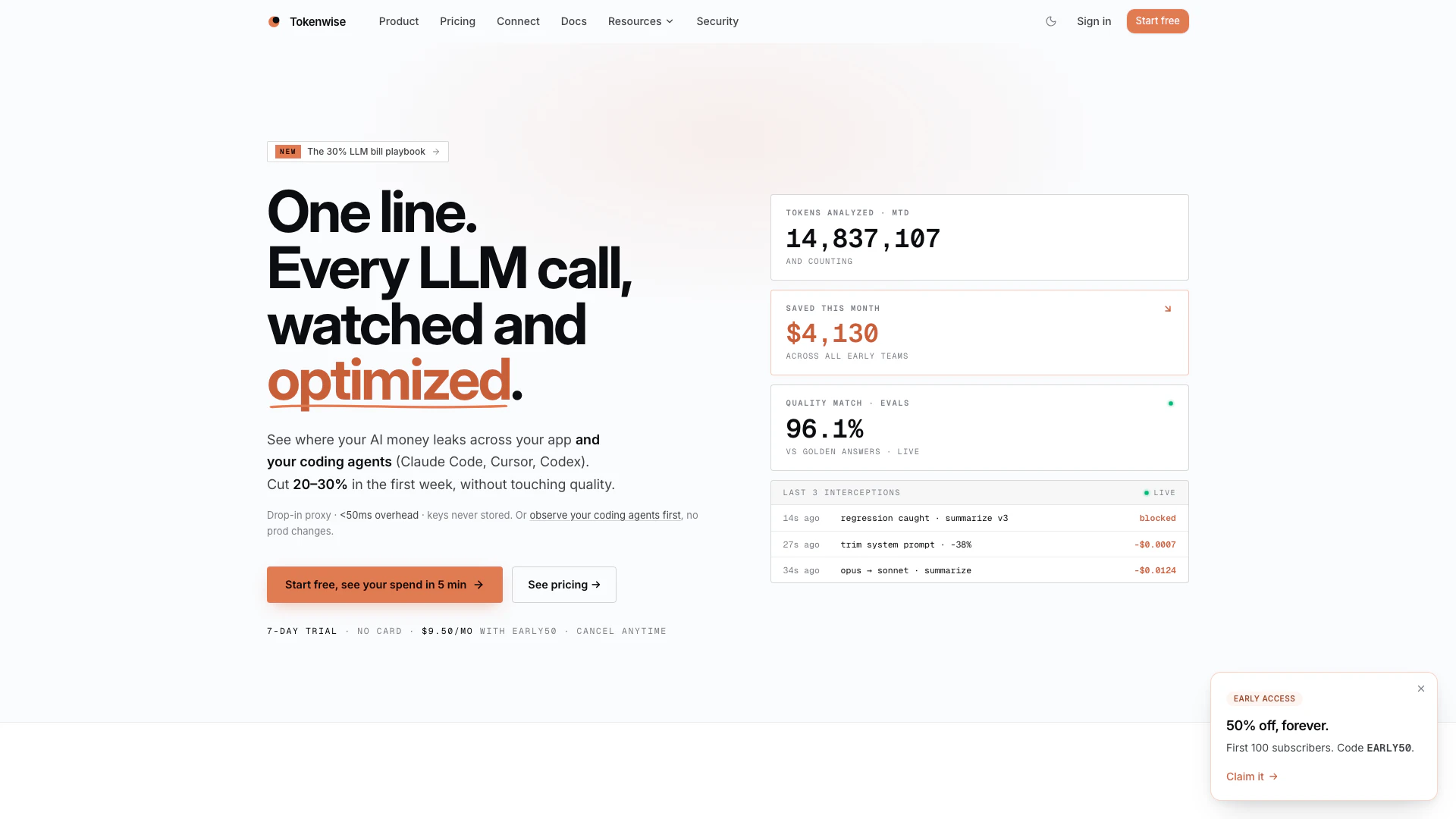
What is Tokenwisehq?
Tokenwisehq is an innovative AI cost and performance optimization tool designed to help businesses save over 30% on their LLM API costs. It operates as a drop-in proxy that requires just one line of code for integration, ensuring minimal overhead while providing detailed insights into API usage. Tokenwisehq allows users to identify cost inefficiencies, optimize API calls, and maintain high-quality outputs without the need for extensive code rewrites or SDK modifications.
How to use Tokenwisehq?
- Connect Your Application: Point your application to the Tokenwisehq drop-in proxy by adding a single line of code, or install it for specific models like Claude Code, Cursor, and Codex.
- Monitor API Calls: Use the observe-only mode to analyze your coding agents and API usage without making any changes to your production environment.
- Identify Cost Leaks: Review detailed reports on API calls, including costs, token usage, and latency, categorized by model or application.
- Implement Fixes: Utilize one-click fixes for model swaps, caching, and prompt optimizations, ensuring each change meets your quality standards before application.
What are the main features of Tokenwisehq?
- Easy Integration: Connect with a single line of code without needing to rewrite your SDK.
- Cost Monitoring: Detailed insights into API costs, token usage, and latency to identify wasteful practices.
- One-Click Fixes: Quickly apply optimizations such as model swaps and prompt trimming without redeploying your application.
- Security Focused: Ensures that provider keys and prompts are never stored or logged, maintaining strict privacy protocols.
- Multi-Provider Support: Works seamlessly with various AI providers, allowing for easy switching and optimization.
Who is Tokenwisehq for?
Tokenwisehq is ideal for development teams, data scientists, and AI engineers who utilize large language models (LLMs) in their applications. It caters to organizations looking to optimize their AI costs and enhance performance without sacrificing quality. Businesses that deploy AI-driven solutions across multiple platforms will find Tokenwisehq particularly beneficial, as it simplifies the management of API calls and enhances cost-efficiency.
What are the use cases of Tokenwisehq?
- Cost Reduction for AI Applications: Organizations can leverage Tokenwisehq to significantly reduce their API costs while maintaining high performance across their AI applications.
- Performance Monitoring: Use Tokenwisehq to monitor the performance of various AI models in real-time, allowing teams to make informed decisions on model usage and optimization.
- Quality Assurance in Development: Implement one-click fixes to ensure that API calls meet quality standards before they affect production, thereby enhancing the reliability of AI outputs.
Tokenwisehq Pros and Cons
Pros
- Cost Savings on LLM APIs: Tokenwise helps users save over 30% on LLM API costs by identifying and fixing inefficiencies in usage, such as unnecessary prompts and cache misses.
- Real-Time Monitoring: The platform provides real-time monitoring of API calls, costs, latency, and errors, allowing users to track their spending and performance effectively.
- Automated Optimization: Tokenwise offers one-click optimizations based on real traffic analysis, helping users to cut waste and improve efficiency without sacrificing quality.
Cons
No cons data detected for this tool
Tokenwisehq Pricing
Indie
For solo makers shipping LLM apps. 7-day trial · no card · EARLY50 applied. +200,000 requests / month, +10 workspaces, +60-day request retention, +Dashboard, requests log & 'What changed', +Cost & latency spike alerts (email), +Weekly insights digest, +Payload storage & request inspector, +Optimization recommendations & semantic cache, +Public REST API — 1,000 calls/hour.
Pro
For small teams running LLMs in production. 7-day trial · no card · EARLY50 applied. +2,000,000 requests / month — 10× Indie, +50 workspaces · 4 role tiers, +180-day request retention, +Everything in Indie, plus: +LLM-as-judge eval engine & interactive rescore, +A/B traffic splits via proxy rules, +Quality regression detector & auto-rollback watchdog, +Daily & monthly budget caps, +Slack & Discord alerts + user webhooks, +Team members & roles, +Public REST API — 10,000 calls/hour, +Priority support · founder Slack.
For the latest pricing, please visit this link: https://tokenwisehq.com/#pricing
Prices are subject to change. Please visit the official website for the most up-to-date pricing information.
Tokenwisehq Compare
Info current as of post date. Offers and availability may vary by location and are subject to change.
Tokenwisehq Q&A
Solo developers and small teams shipping with the Vercel AI SDK, Cursor, Claude Code, Lovable, Bolt, or a plain OpenAI or Anthropic SDK. If your monthly LLM bill is between $50 and $2,000, Tokenwise is built for you.
Tokenwisehq Alternatives
DeepSeek focuses on pioneering general AI technologies and models.
- Other
- Large Language Models (LLMs)
- AI Development Tools
- Ai Model Fine Tuning Tools

Explore cutting-edge AI models with Deepseek.
- Developer Tools
- AI Development Tools
- Ai Model Fine Tuning Tools
- AI Cloud Computing Platforms
OpenAI Codex enhances coding efficiency with AI-driven task support.
- Developer Tools
- AI Coding Assistants
- AI Development Tools
- AI Prompt Engineering Tools